
|
Random variables and probability distributions
 Random Variable
Random Variable
The outcome of an experiment need not be a number, for example, the outcome when a coin is tossed can be 'heads' or 'tails'. However, we often want to represent outcomes as numbers. A random variable is a function that associates a unique numerical value with every outcome of an experiment. The value of the random variable will vary from trial to trial as the experiment is repeated. There are two types of random variable - discrete and continuous. A random variable has either an associated probability distribution (discrete random variable) or probability density function (continuous random variable). Examples
Expected Value
The expected value (or population mean) of a random variable indicates its average or central value. It is a useful summary value (a number) of the variable's distribution. Stating the expected value gives a general impression of the behaviour of some random variable without giving full details of its probability distribution (if it is discrete) or its probability density function (if it is continuous). Two random variables with the same expected value can have very different distributions. There are other useful descriptive measures which affect the shape of the distribution, for example variance. The expected value of a random variable X is symbolised by E(X) or µ.
See also sample mean.
Variance
The (population) variance of a random variable is a non-negative number which gives an idea of how widely spread the values of the random variable are likely to be; the larger the variance, the more scattered the observations on average. Stating the variance gives an impression of how closely concentrated round the expected value the distribution is; it is a measure of the 'spread' of a distribution about its average value. Variance is symbolised by V(X) or Var(X) or
Notes
See also sample variance.
Probability Distribution
The probability distribution of a discrete random variable is a list of probabilities associated with each of its possible values. It is also sometimes called the probability function or the probability mass function.
It satisfies the following conditions:
Cumulative Distribution Function
All random variables (discrete and continuous) have a cumulative distribution function. It is a function giving the probability that the random variable X is less than or equal to x, for every value x.
For a discrete random variable, the cumulative distribution function is found by summing up the probabilities as in the example below. For a continuous random variable, the cumulative distribution function is the integral of its probability density function.
Probability Density Function
The probability density function of a continuous random variable is a function which can be integrated to obtain the probability that the random variable takes a value in a given interval.
If f(x) is a probability density function then it must obey two conditions:
Discrete Random Variable
A discrete random variable is one which may take on only a countable number of distinct values such as 0, 1, 2, 3, 4, ... Discrete random variables are usually (but not necessarily) counts. If a random variable can take only a finite number of distinct values, then it must be discrete. Examples of discrete random variables include the number of children in a family, the Friday night attendance at a cinema, the number of patients in a doctor's surgery, the number of defective light bulbs in a box of ten. Compare continuous random variable.
Continuous Random Variable
A continuous random variable is one which takes an infinite number of possible values. Continuous random variables are usually measurements. Examples include height, weight, the amount of sugar in an orange, the time required to run a mile. Compare discrete random variable.
Independent Random Variables
Two random variables X and Y say, are said to be independent if and only if the value of X has no influence on the value of Y and vice versa.
Knowledge of the value of X does not effect the probability distribution of Y and vice versa. Thus there is no relationship between the values of independent random variables.
Probability-Probability (P-P) Plot
A probability-probability (P-P) plot is used to see if a given set of data follows some specified distribution. It should be approximately linear if the specified distribution is the correct model. The probability-probability (P-P) plot is constructed using the theoretical cumulative distribution function, F(x), of the specified model. The values in the sample of data, in order from smallest to largest, are denoted x(1), x(2), ..., x(n). For i = 1, 2, ....., n, F(x(i)) is plotted against (i-0.5)/n. Compare quantile-quantile (Q-Q) plot.
Quantile-Quantile (QQ) Plot
A quantile-quantile (Q-Q) plot is used to see if a given set of data follows some specified distribution. It should be approximately linear if the specified distribution is the correct model. The quantile-quantile (Q-Q) plot is constructed using the theoretical cumulative distribution function, F(x), of the specified model. The values in the sample of data, in order from smallest to largest, are denoted x(1), x(2), ..., x(n). For i = 1, 2, ....., n, x(i) is plotted against F-1((i-0.5)/n). Compare probability-probability (P-P) plot.
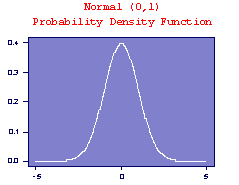
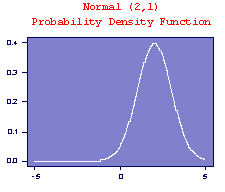
Normal Distribution
Normal distributions model (some) continuous random variables. Strictly, a Normal random variable should be capable of assuming any value on the real line, though this requirement is often waived in practice. For example, height at a given age for a given gender in a given racial group is adequately described by a Normal random variable even though heights must be positive.
This probability density function (p.d.f.) is a symmetrical, bell-shaped curve, centred at its expected value µ. The variance is Many distributions arising in practice can be approximated by a Normal distribution. Other random variables may be transformed to normality. The simplest case of the normal distribution, known as the Standard Normal Distribution, has expected value zero and variance one. This is written as N(0,1). Examples
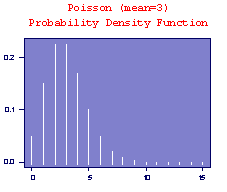
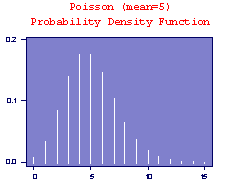
Poisson Distribution
Poisson distributions model (some) discrete random variables. Typically, a Poisson random variable is a count of the number of events that occur in a certain time interval or spatial area. For example, the number of cars passing a fixed point in a 5 minute interval, or the number of calls received by a switchboard during a given period of time.
The following requirements must be met:
The Poisson distribution has expected value E(X) = m and variance V(X) = m; i.e. E(X) = V(X) = m. The Poisson distribution can sometimes be used to approximate the Binomial distribution with parameters n and p. When the number of observations n is large, and the success probability p is small, the Bi(n,p) distribution approaches the Poisson distribution with the parameter given by m = np. This is useful since the computations involved in calculating binomial probabilities are greatly reduced. Examples
Binomial Distribution
Binomial distributions model (some) discrete random variables. Typically, a binomial random variable is the number of successes in a series of trials, for example, the number of 'heads' occurring when a coin is tossed 50 times.
The trials must meet the following requirements:
The Binomial distribution has expected value E(X) = np and variance V(X) = np(1-p). Examples
Geometric Distribution
Geometric distributions model (some) discrete random variables. Typically, a Geometric random variable is the number of trials required to obtain the first failure, for example, the number of tosses of a coin untill the first 'tail' is obtained, or a process where components from a production line are tested, in turn, until the first defective item is found.
The trials must meet the following requirements:
The Geometric distribution has expected value E(X)= 1/(1-p) and variance V(X)=p/{(1-p)2}. The Geometric distribution is related to the Binomial distribution in that both are based on independent trials in which the probability of success is constant and equal to p. However, a Geometric random variable is the number of trials until the first failure, whereas a Binomial random variable is the number of successes in n trials. Examples
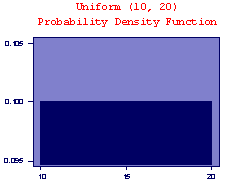
Uniform Distribution
Uniform distributions model (some) continuous random variables and (some) discrete random variables. The values of a uniform random variable are uniformly distributed over an interval. For example, if buses arrive at a given bus stop every 15 minutes, and you arrive at the bus stop at a random time, the time you wait for the next bus to arrive could be described by a uniform distribution over the interval from 0 to 15.
A discrete uniform distribution has equal probability at each of its n values. A continuous random variable X is said to follow a Uniform distribution with parameters a and b, written The Uniform distribution has expected value E(X)=(a+b)/2 and variance {(b-a)2}/12. Example
Central Limit Theorem
The Central Limit Theorem states that whenever a random sample of size n is taken from any distribution with mean µ and variance This is very useful when it comes to inference. For example, it allows us (if the sample size is fairly large) to use hypothesis tests which assume normality even if our data appear non-normal. This is because the tests use the sample mean
|
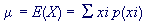
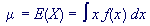
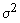

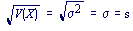

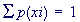
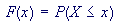
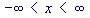
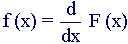
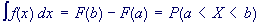
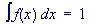
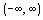 is said to follow a Normal distribution with parameters µ and
is said to follow a Normal distribution with parameters µ and 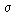 if it has probability density function
if it has probability density function
![f(x) = {1/sqrt(2.pi.sigma^2)}.exp[-.5{(x-mu)/sigma}^2]](../images/normdist.gif)
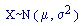
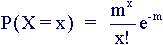
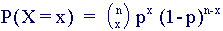
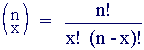




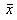 will be approximately normally distributed with mean µ and variance
will be approximately normally distributed with mean µ and variance